The left column is based on 20 trials having 8 and 11 successes. In addition note that the peaks are more narrow for 40 trials rather than 20.
 Maximum Likelihood Estimate And Logistic Regression Simplified Pavan Mirla
Maximum Likelihood Estimate And Logistic Regression Simplified Pavan Mirla
All possible trees are considered.

Maximum likelihood for dummies. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. This probability is summarized in what is called the likelihood function. If you dont know what any of these are Gradient Descent was explained in the Linear Regression post and an explanation of Maximum Likelihood for Machine Learning can be found here.
Theta in order to predict y given x. Neural network as a model generator. This content is available under a CC BY-NC 40 International license Creative Commons Attribution-NonCommercial 40.
Maximize sum i to n log P yixi. Therefore their maxima wrt. Viewed 161 times 2.
I have tried to read the paper. H The maximum likelihood estimator can readily be generalized to the case where our goal is to estimate a conditional probability P y x. 1 begingroup I have tried to get my head around the concept of TMLE but most references seem to be written by people who despise being understood or maybe I am just hebetudinous.
Both panels were computed using the binopdf function. Targeted Maximum Likelihood Estimation for dummies. The parameter values are found such that they maximise the likelihood that the process described by the model produced the data that were actually observed.
Now for the maximum likelihood ML inference of parameters assuming that these parameters are shared across time during inference of hidden state variables you need to use the non-causal version of Kalman filter that is the forward-backward Kalman filter RTS smoothing. We can use an iterative optimisation algorithm like Gradient Descent to calculate the parameters of the model the weights or we can use probabilistic methods like Maximum likelihood. Notice that the maximum likelihood is approximately 106for 20 trials and 1012for 40.
The formula of the likelihood function is. Maximum Likelihood EstimationMLE Likelihood Function. The right column is based on 40 trials having 16 and 22 successes.
Constructing the likelihood function. The logic of maximum likelihood is both. Given observations MLE tries to estimate the parameter which maximizes the likelihood function.
Remember dont interpret those as probabilities. Ask Question Asked 1 year 3 months ago. The word is a portmanteau coming from probability unit.
Moreover classifying observations. The objective of maximum likelihood ML estimation is to choose values for the estimated parameters betas that would maximize the probability of observing the Y values in the sample with the given X values. If you hang out around statisticians long enough sooner or later someone is going to mumble maximum likelihood and everyone will knowingly nod.
In the lower I varied the values of the p parameter. Maximum likelihood estimation MLE is a technique used for estimating the parameters of a given distribution using some observed data. In the upper panel I varied the possible results.
The more probable the sequences given the tree the more the tree is preferred. In statistics a probit model is a type of regression where the dependent variable can take only two values for example married or not married. The purpose of the model is to estimate the probability that an observation with particular characteristics will fall into a specific one of the categories.
P b x p x b p b p x p b x p x b p x And since p x is constant for fixed x we have that. The binomial probability distribution function given 10 tries at p 5 top panel and the binomial likelihood function given 7 successes in 10 tries bottom panel. If we have binary data the probability of each.
The above definition may still sound a little cryptic so lets go through an example to help understand this. The probability distribution function is discrete because. This is actually the most common situation because it forms the basis for most supervised learning.
After that you carry out ML estimation as usual. P b x p x b k. Intuitive explanation of maximum likelihood estimation.
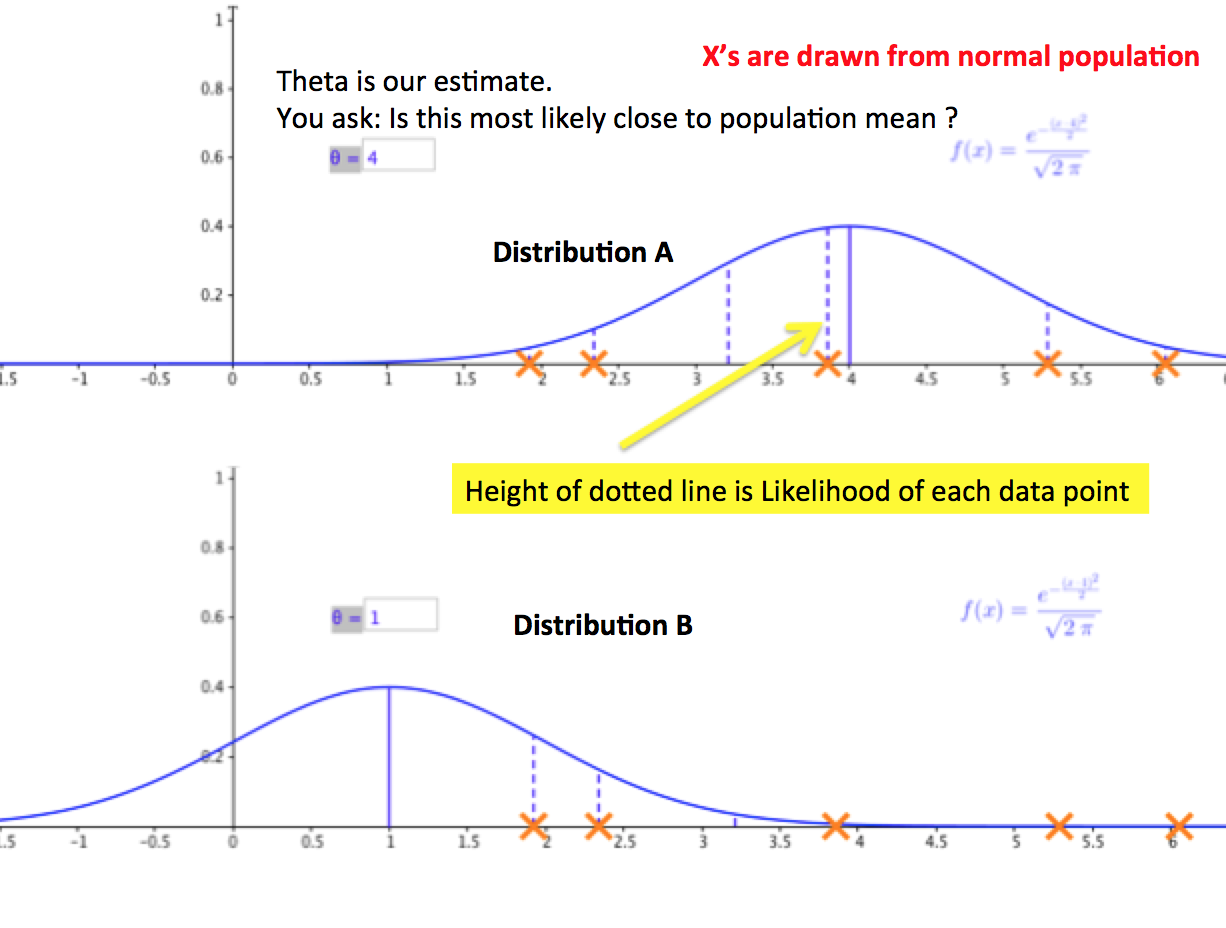
Lets calculate the likelihood of θ05 a fair coin given toss HHHHHHH Its equal to fH 05 multiplied by itself 7 times. Maximum likelihood is the third method used to build trees. Maximum likelihood estimation is a method that determines values for the parameters of a model.
Likelihood provides probabilities of the sequences given a model of their evolution on a particular tree. The likelihood of θ10 is 17 1. The Precision of the Maximum Likelihood Estimator Intuitively the precision of ˆ depends on the curvature of the log-likelihood function near ˆ If the log-likelihood is very curved or steep around ˆ then will be precisely estimated.
In other words the posterior is a scaled version of the likelihood. In statistics maximum likelihood estimation MLE is a method of estimating the parameters of a probability distribution by maximizing a likelihood function so that under the assumed statistical model the observed data is most probable. The maximum likelihood estimate is that set of regression coefficients for which the probability of getting the data we have observed is maximum.
It has been published as is and may contain inaccuracies or culturally inappropriate references that do not necessarily reflect the official policy or position of the University of Lincoln or the International Bomber Command Centre. It just tells us that the latter is far more likely. Active 8 months ago.